MAKER: A million-step LLM task with zero errors (MDAPs explained)
Updated on November 13, 2025
MAKER million-step zero-error LLM reasoning visualization
If you want AI to run long workflows, you need it to execute a lot of steps without drifting. Today, LLMs still struggle once a task gets long and dependent. Even a small per-step error rate compounds fast.
This is the problem MAKER targets. The paper reports a system that solves a task requiring over one million LLM steps with zero errors, using an approach the authors call Massively Decomposed Agentic Processes (MDAPs).
If you are building agent workflows, MAKER is a useful reference for how to design for reliability instead of hoping a single model will never slip.

The LLM Reliability Cliff
Current LLMs suffer from a persistent error rate that prevents scale-up. When tasks involve many dependent logical steps, even small errors compound quickly, leading to catastrophic failure.
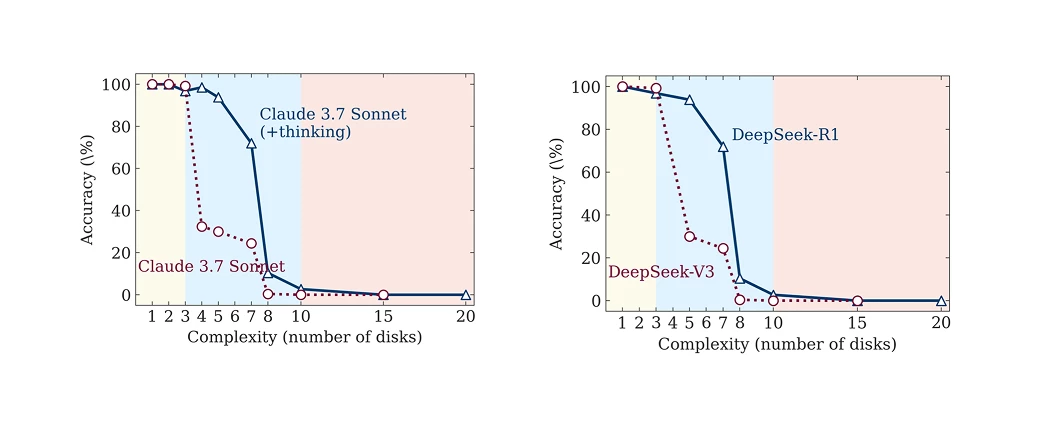
Experiments using benchmarks like the Towers of Hanoi vividly demonstrate this “reliability cliff”. Standard models perform well on simple versions but fail completely once the task crosses about eight disks. A system with just a 1% per-step error rate is expected to fail after only 100 steps of a million-step task.
MAKER tackles this by shifting the focus from constantly improving a single model to building a system that expects mistakes and corrects them locally.
Understanding MAKER: Scaling Intelligence Through Structure
MAKER stands for Maximal Agentic decomposition, first-to-ahead-by-K Error correction, and Red-flagging. It is an implementation of the MDAP framework.
The main idea is that reliability can come from extreme decomposition plus local error correction. Instead of relying on continual model improvements, the system design does more of the work.
MAKER relies on three core components:
1. Maximal Agentic Decomposition (MAD)
For long tasks, LLMs performing multi-step reasoning often become unreliable as their context increases. MAD solves this by breaking the task into the smallest possible subtasks, assigning each to a focused microagent.
- Microagents, Micro-roles: Each agent is assigned only a single subtask (maximal decomposition, m=1). This limits the agent’s context to the minimal information needed for that single step.
- Efficiency: This extreme focus allows the use of smaller, non-reasoning LLMs with limited context sizes, which were found to be more cost-effective for long-range tasks within the MAKER framework.
2. First-to-ahead-by-k Voting
Modularity enables effective and scalable error correction at the subtask level. MAKER uses a multi-agent voting scheme: multiple agents independently attempt to solve the same single step.
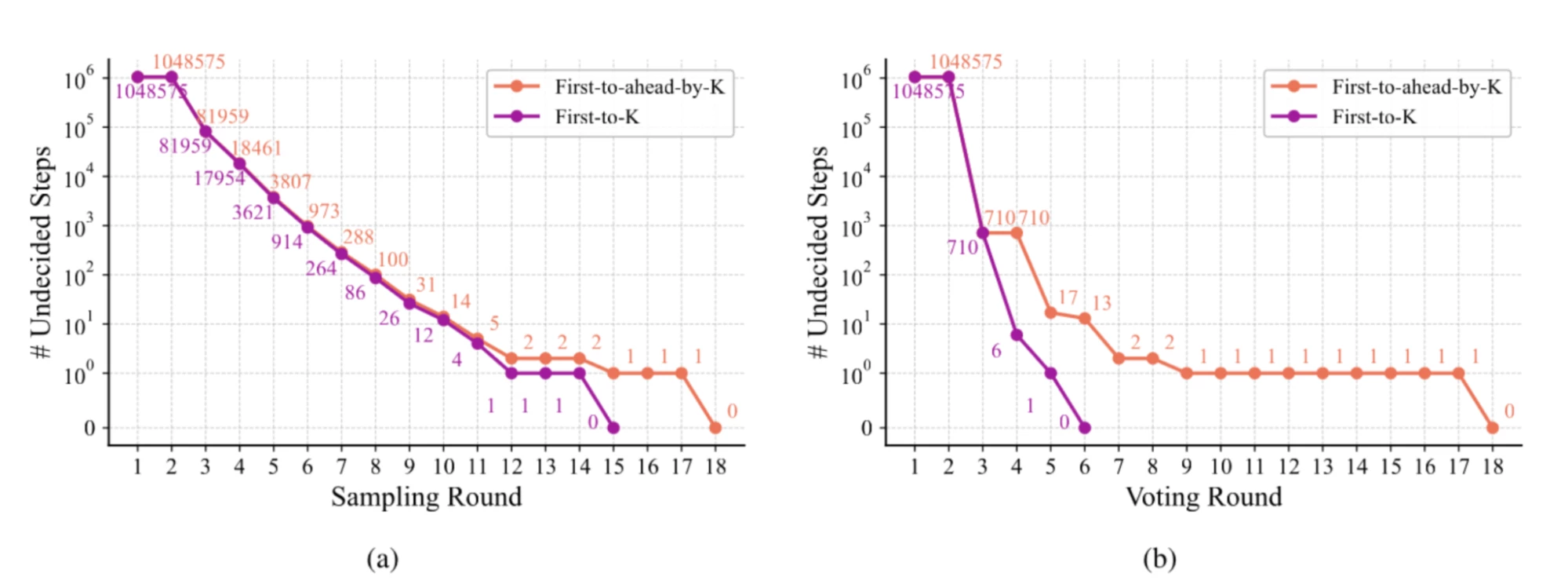
- Local Consensus: Candidate actions are sampled until one action has achieved k more votes than any other. This is known as “First-to-ahead-by-k voting”.
- Scaling Efficiency: The necessary vote threshold, k_min, grows only logarithmically (Θ(ln s)) with the total number of steps (s). This is a key finding: when combined with MAD, the overall expected cost of solving the entire task scales log-linearly (Θ(s ln s)). In contrast, if agents handle multiple steps (m>1), the cost grows exponentially.
3. Red-Flagging
To boost the per-step success rate (p), MAKER uses “red-flagging” to discard responses that indicate increased risk of errors, especially correlated errors.
- Indicators of Confusion: MAKER flags responses that are overly long or incorrectly formatted. Preliminary experiments showed that longer answers tend to have more errors, and incorrect formatting often correlates with flawed reasoning.
- Mitigation: By discarding these responses and resampling, MAKER increases the success rate (p) and meaningfully reduces correlated errors, ensuring localized failures don’t propagate.
The Proof: Solving the 20-Disk Towers of Hanoi
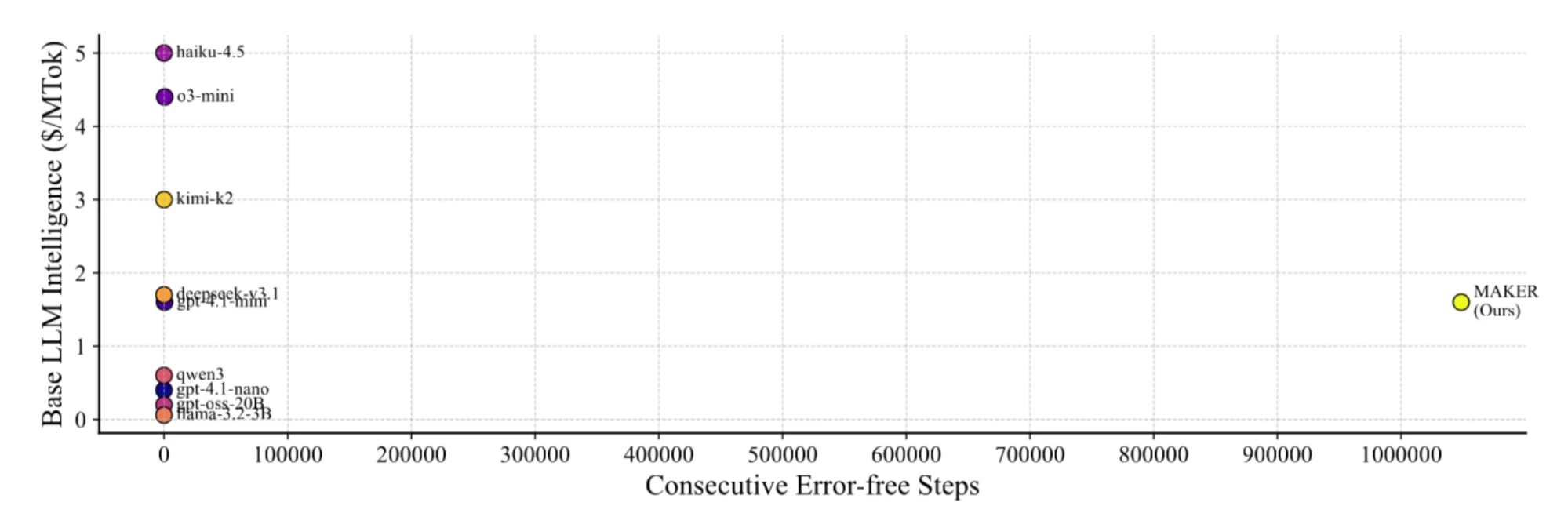
To validate MAKER, researchers applied it to the Towers of Hanoi puzzle with 20 disks. This configuration requires 2²⁰ - 1, or 1,048,575, dependent steps. Every single step had to be executed correctly.
Using gpt-4.1-mini (a non-reasoning model chosen for its cost-effectiveness), and setting the voting threshold to k=3, the full MAKER system solved the problem perfectly. This successful execution of over one million LLM steps with zero errors establishes that scaling LLM-based systems to large time horizons is possible.
The process exhibited exponential convergence toward a zero-error solution, confirming MAKER’s theoretical efficiency.
What this means for building agents
The MAKER architecture has a few useful takeaways for developers, designers, and solo founders building agent workflows:
1. Development and Agent Design
MAKER’s success hinges on Extreme Decomposition, mirroring principles found in microservices architecture:
- Modularity: Each microagent can be tailored to a specific task.
- Independent Development: Agents can be updated and tested in isolation.
- Design for Failure: The system is designed to tolerate the failure of individual agents through voting and error correction.
For developers, this suggests that investment should focus on creating highly specialized, minimal-context microagents rather than continually chasing the latest, largest monolithic LLM.
2. Scaling and Cost Management (For Solo Founders)
By using MDAPs, you can maintain a high probability of success for large tasks by increasing k (the vote threshold). The system’s cost scales log-linearly with the number of steps.
- This framework allows for the selection of the most cost-effective LLM (c/p minimized). Surprisingly, smaller, non-reasoning models often provide the best reliability-per-dollar when used in MAKER.
- The total cost of running MAKER scales much more efficiently than using a single agent or a partially decomposed system.
3. Safety and Control (For Founders and Enthusiasts)
MAKER presents an alternative path to advanced AI that can reduce risk compared to relying on ever-smarter single models.
- Transparency and Auditing: Because each step has a clearly defined and limited focus, the agents’ actions are easier to sandbox, audit, and control.
- Reduced Collusion Risk: Running multiple focused agents independently on each step substantially reduces the ability of agents to collude to produce harmful actions.
- Model Size and Risk: The ability to use smaller LLMs for the vast majority of the work mitigates risks associated with powerful, less-controlled models.
The Future of Agentic AI
While MAKER demonstrated flawless execution of a known plan in the Towers of Hanoi, the next frontier is extending this framework to cover creative work like planning, idea generation, and verification.
By decomposing the entire problem-solving pipeline, including the creative parts, and applying MDAP principles, developers can automate complex processes where the total number of steps and the specific subtask types are unknown beforehand.
MAKER is a good example of a broader point: systems design matters. If you want reliability over long horizons, you may need decomposition, checks, and retries even more than a bigger model.
Launching an AI tool? Here is a list of AI directories you can submit to, plus a quick basic SEO guide for getting the post-launch stuff right.
MAKER was described in the preprint “Solving a Million-Step LLM Task with Zero Errors,” authored by Elliot Meyerson, Giuseppe Paolo, Roberto Dailey, and others, and featured in the blog post “Shattering the Illusion: MAKER Achieves Million-Step, Zero-Error LLM Reasoning”.